One of my largest clients is undergoing a multi-week project to implement a new backup and disaster recovery infrastructure based on Veeam Backup & Replication. This client is a midrange customer in the retail industry with over 30,000 employees worldwide and multiple locations in the EU.
What makes this project intriguing is that the client operates a multi-host infrastructure using VMware vSphere, Microsoft Hyper-V (without cluster features), Oracle KVM, and OVS. In total, there are more than 30 hypervisor systems being operated internationally. In addition to the mentioned virtualization solutions, the client also utilizes physical systems that need to be considered in the backup strategy.
In accordance with my standard Veeam Advanced Deployment approach, the following components are being deployed within the Veeam infrastructure:
- VBR Server (Veeam Management) – virtual
- Repository & Proxy Server – physical
- Enterprise Manager Server – virtual
- Management Server (Jump-Host) – virtual
- Veeam Hardened Repository with Immutability (Linux) – physical
The virtual systems are hosted on the client’s vSphere infrastructure, while the physical servers consist of HPE Apollo Servers with local HDDs for mass storage. A total of 2 RAID6 sets per system have been configured, following current best practices, with a full stripe size of 1MB.
Due to the size and licensing costs of MSSQL, PostgreSQL is chosen as the database system for Veeam VBR and the Enterprise Manager. This decision is made because the 10GB limitation of MSSQL Express Edition is insufficient for the client’s needs.
Scale-Out Repositories:
As there are a total of 2 RAID sets, and consequently, 2 logical drives per server, a Scale-Out Repository has been configured for each server. These Scale-Out Repositories serve as the destination for all backup jobs and backup copy jobs:



Veeam Proxies:
Since the physical Windows repository server has redundant connectivity to the existing SAN infrastructure and the storage for the vSphere environment has been configured to present storage LUNs to the server, we can employ Direct SAN Access in this scenario. Consequently, this server is also configured as a Veeam proxy. Given its generous hardware specifications in terms of compute performance, it is also utilized as a proxy for agents and additional workloads. This is particularly relevant concerning firewall rules and hardening measures.

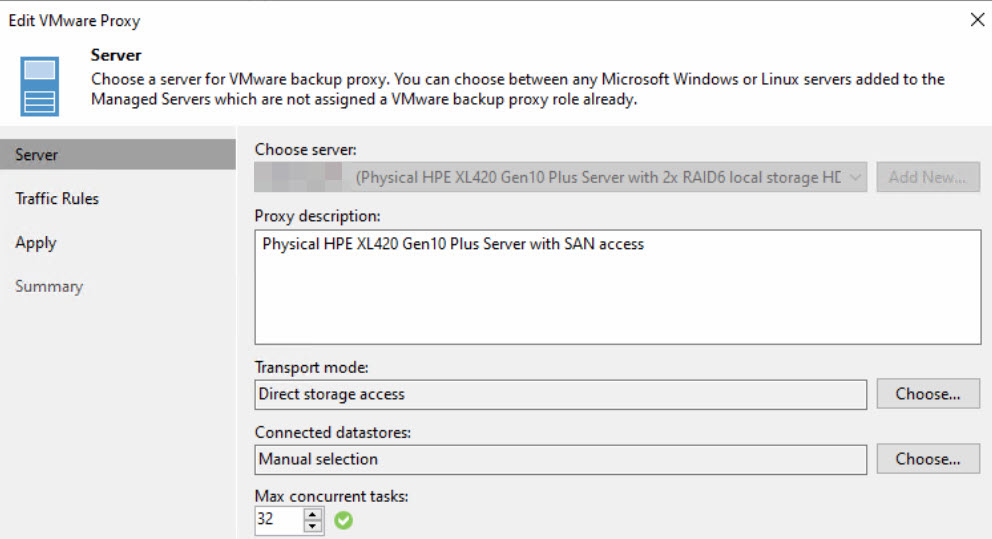
By the way, two local SSDs were configured in RAID1 as the vPower Cache, and they also serve as the path for the OS installation on both systems. This request came from the customer and was gladly implemented.
Integration Veeam Hardened Repository:
To establish the first level with increased security, as mentioned earlier, a hardware server with required computing and storage capacity was configured as a Veeam Hardened Repository Server. Immutability has been enabled both on Wasabi and within Veeam, ensuring that backups cannot be deleted or modified for the specified duration.
Relevant tests have validated the immutability of the backups:
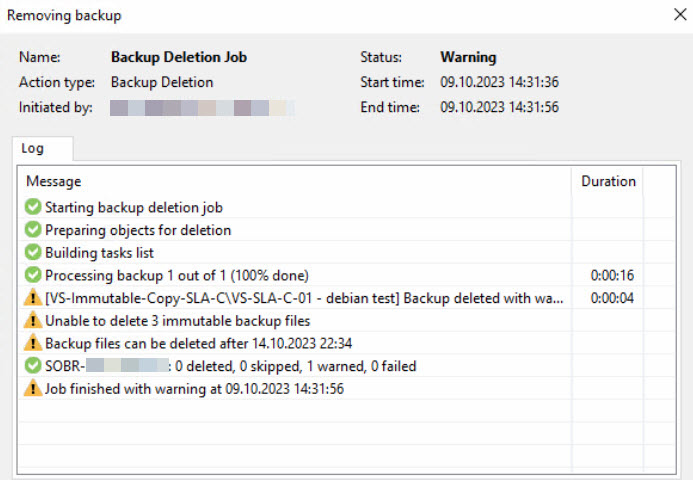
This Linux repository primarily serves for high-performance and compute-close data recovery in case the primary backup repository (based on Windows) is unavailable. The server itself only assumes the role of a repository and is not configured as a proxy or similar.
To mitigate the risk of excessive storage utilization, the client has defined a retention period of 7 days for both immutability and the backup copy jobs themselves towards the Veeam Hardened Repository.
Integration Wasabi Cloud:
Since the client intends to cost-effectively offload between 100TB and 150TB of data to a cloud solution, they have proactively conducted initial tests with the Wasabi cloud. Given its favorable price-performance ratio, I fully support this approach and have revised the installation and configuration of the solution as part of the project.
Ultimately, the goal is to accommodate three different retention periods within Wasabi, which led to the creation of three separate buckets, one for each retention period. This mirrors the retentions/SLAs already defined in the primary backup jobs. Unlike the Veeam Hardened Repository on Linux, Wasabi does not impose a “hard” storage limit, allowing for a clean implementation of these SLA retentions.
Immutability has also been activated here, ensuring that the backups cannot be deleted or modified for the specified duration.
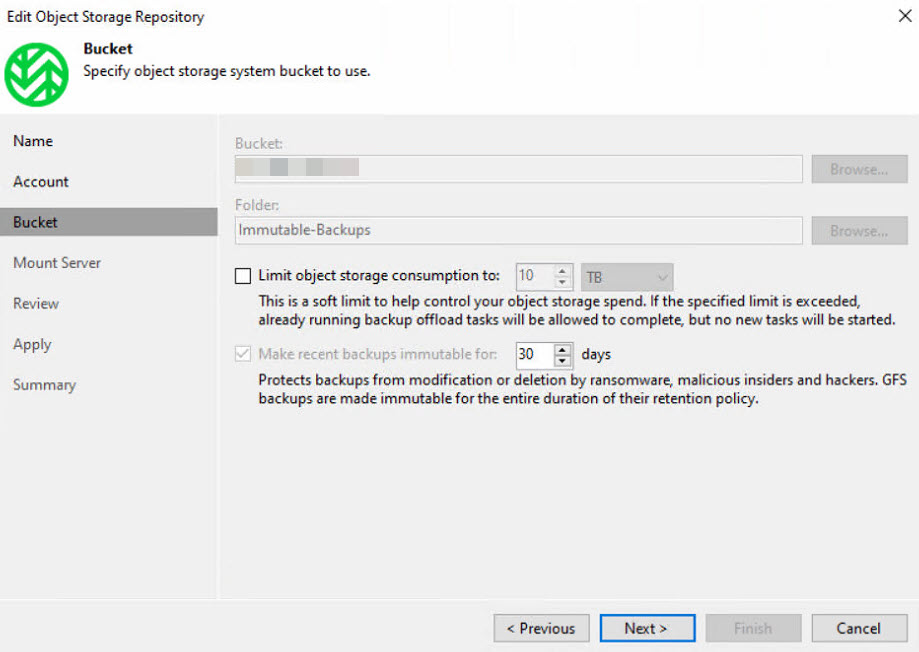
It’s important to note that versioning within the Wasabi cloud must be enabled to ensure proper configuration of immutability in Veeam! The following settings have been configured within the Wasabi cloud:
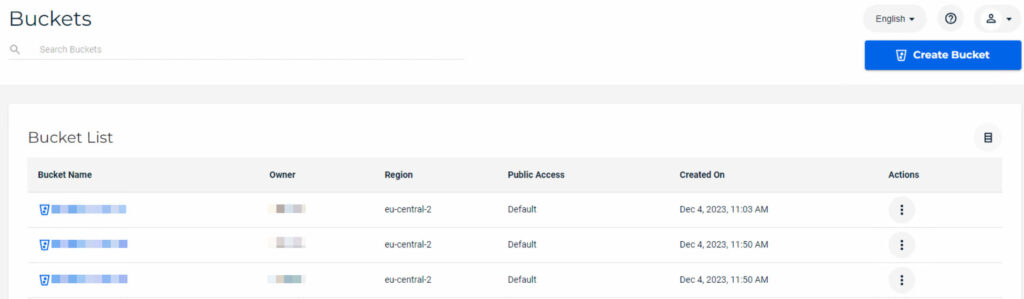
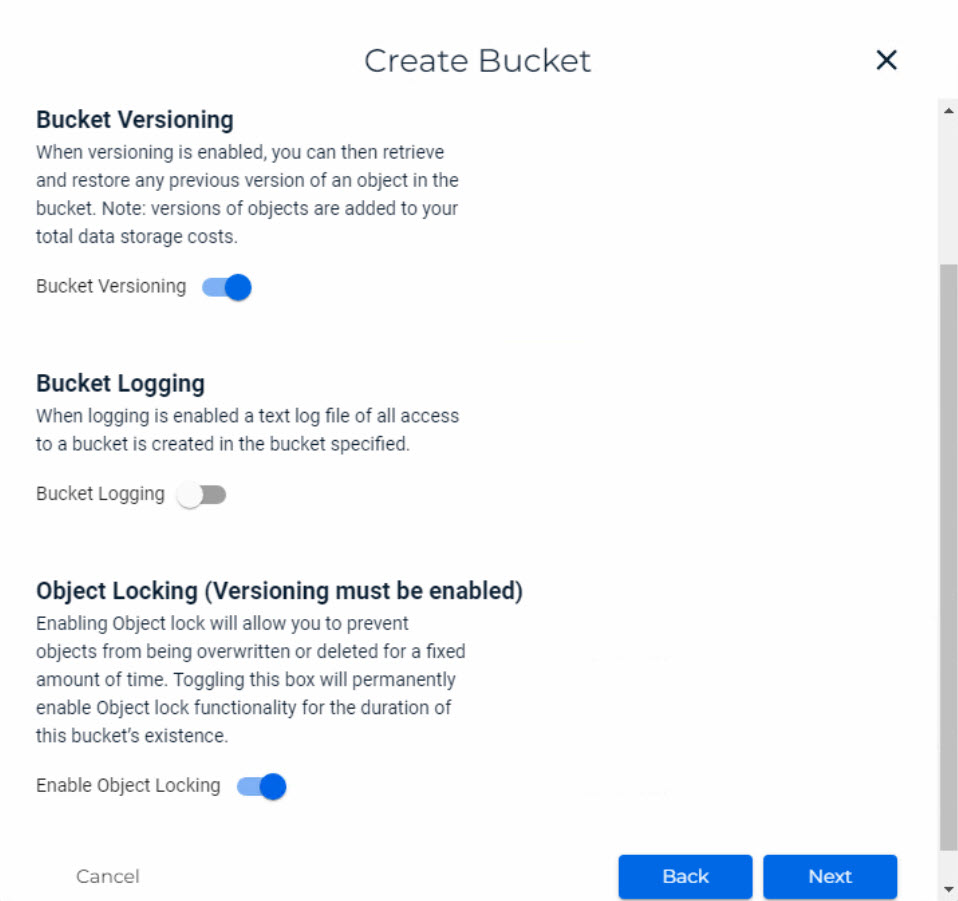
Integration vSphere environment:
The client utilizes a vSphere infrastructure consisting of 6 ESXi hosts, which have been added to Veeam. As is customary, I have created not only the vCenter (as the client operates only one) but also each individual ESXi host separately, identified by their respective IP addresses. This configuration allows the client to perform restores directly to one of the hosts in case of a failure or when the vCenter is powered off.
Integration Hyper-V environment:
As the client operates a Microsoft SQL AlwaysOn cluster across a total of 4 Hyper-V hosts and does not have a Microsoft Failover Cluster for VMs in place, all 4 hosts have been added individually as standalone hosts in Veeam. Since this environment is dedicated and “isolated,” solely serving the purpose of the AlwaysOn cluster, no additional configuration has been carried out here.
Agent design (Protection Groups):
A unique aspect with this client is their geographically dispersed external site infrastructure, which can be somewhat complex and not entirely transparent to the client. This infrastructure comprises various OVS, KVM, and physical systems. The client acquired these sites, and the management of most of these systems is in the hands of software vendors or dedicated partners. These systems include both Windows and Linux environments.
The SLA (Service Level Agreement) principle configured for vSphere and Hyper-V jobs will not be applied in this context. This is because external service providers handle backups at different levels, including database backups.
Protection groups have been defined based on the location and configured as follows:
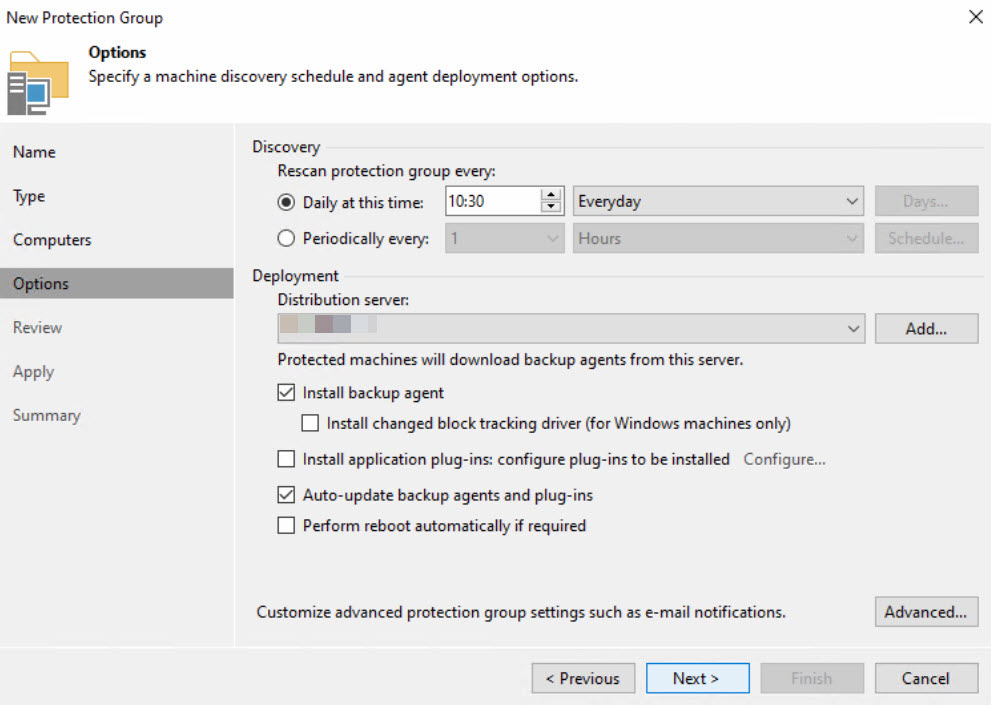
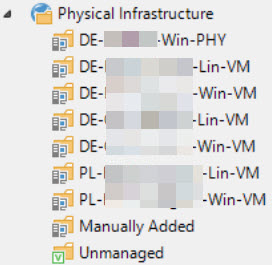
At the customer’s request, the country code is incorporated into the name of the protection group.
Agent Backup Job design:
The backup jobs for the agents were created based on the protection groups and configured as follows:

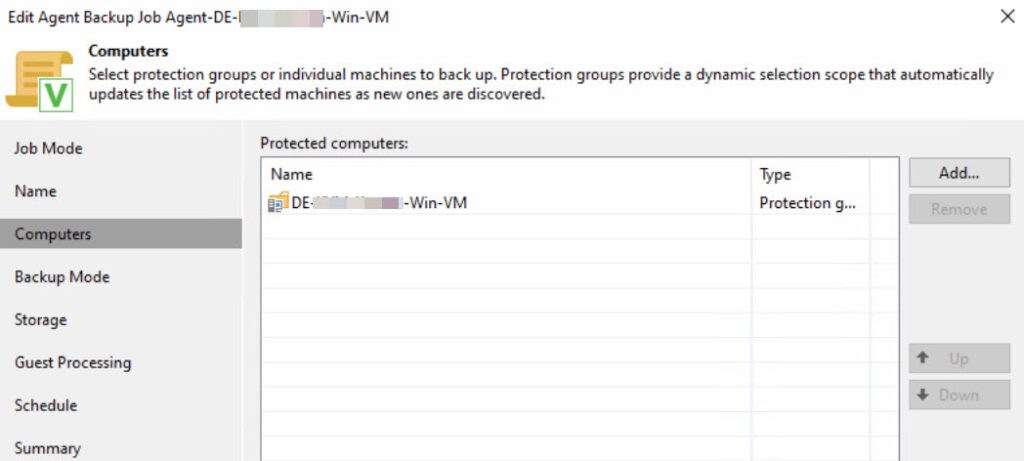
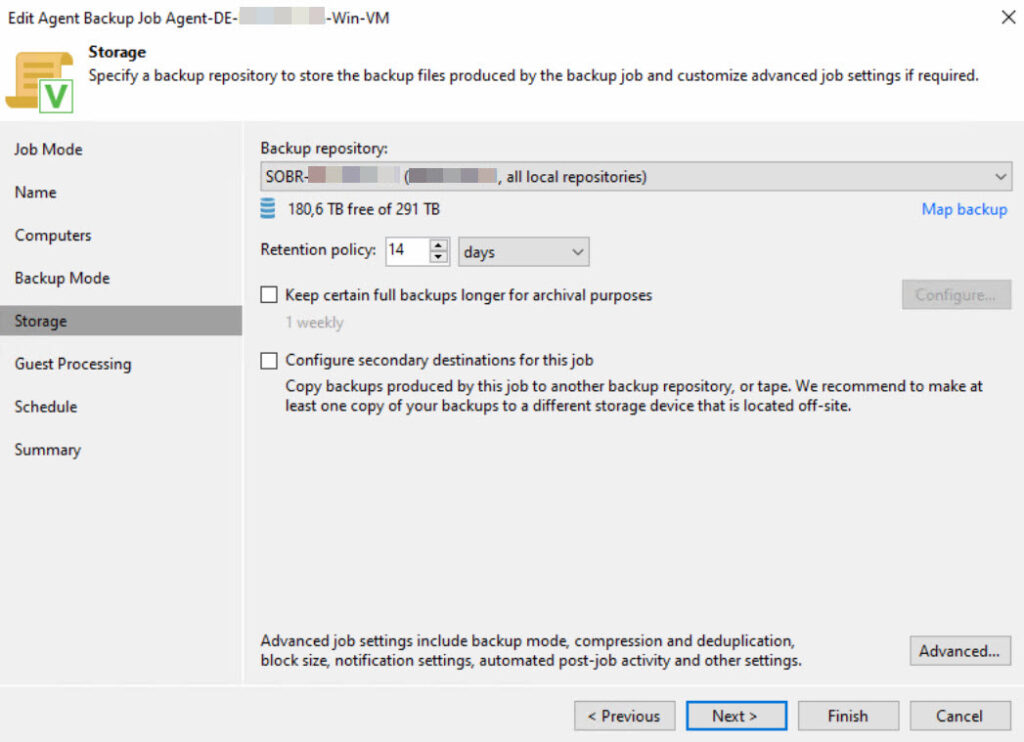
Important: Since a protection group can contain both Windows and Linux systems, but an agent backup job is designed for either Windows or Linux, this must be taken into account when designing the protection groups. In my experience, I always separate the groups by Windows and Linux to streamline the process and enhance transparency when creating agent backup jobs.
The client does not have specific SLAs or similar requirements for the agents. Therefore, at the customer’s request, a retention period of 14 days will be applied across the board.
SLA declaration / vSphere tags:
For the client’s primary systems, which include the vSphere and Hyper-V environments, a collaboration with the client resulted in the establishment of an SLA (Service Level Agreement) declaration. This declaration has been incorporated into the job design and also integrated into the design of vSphere tags, thus applying the following SLAs to both environments:
SLA A (highest priority): 30-day retention in the primary repository, 7-day immutable copy on Linux, 30-day immutable copy on Wasabi.
SLA B (medium priority): 14-day retention in the primary repository, 7-day immutable copy on Linux, 14-day immutable copy on Wasabi.
SLA C (low priority): 7-day retention in the primary repository, 7-day immutable copy on Linux, 7-day immutable copy on Wasabi.
The goal is to ensure that in case of a disaster, the client knows the sequence in which to restore the systems, starting with SLA A. Since Hyper-V lacks tags or similar features without the use of SCVMM (System Center Virtual Machine Manager), a manual assignment of VMs to the corresponding jobs was carried out for Hyper-V.
vSphere Job design:
VS-SLA-A-01 (Numbering continues): All VMs in the vSphere environment with SLA A (as mentioned above), based on corresponding vSphere tags. Application Aware Processing and Guest File System Indexing (GFSI) are also declared via vSphere tags.
Retention: 30 days on the SOBR (local hard drives of the Windows backup server).
VS-SLA-B-01 (Numbering continues): All VMs in the vSphere environment with SLA B (as mentioned above), based on corresponding vSphere tags. Application Aware Processing and Guest File System Indexing (GFSI) are also declared via vSphere tags.
Retention: 14 days on the SOBR (local hard drives of the Windows backup server).
VS-SLA-C-01 (Numbering continues): All VMs in the vSphere environment with SLA C (as mentioned above), based on corresponding vSphere tags. Application Aware Processing and Guest File System Indexing (GFSI) are also declared via vSphere tags.
Retention: 7 days on the SOBR (local hard drives of the Windows backup server).
vSphere AAP and GFSI:
Both AAP (Application Aware Processing) and GFSI (Guest File System Indexing) have been represented within the vSphere environment through tags and configured in Veeam as follows:
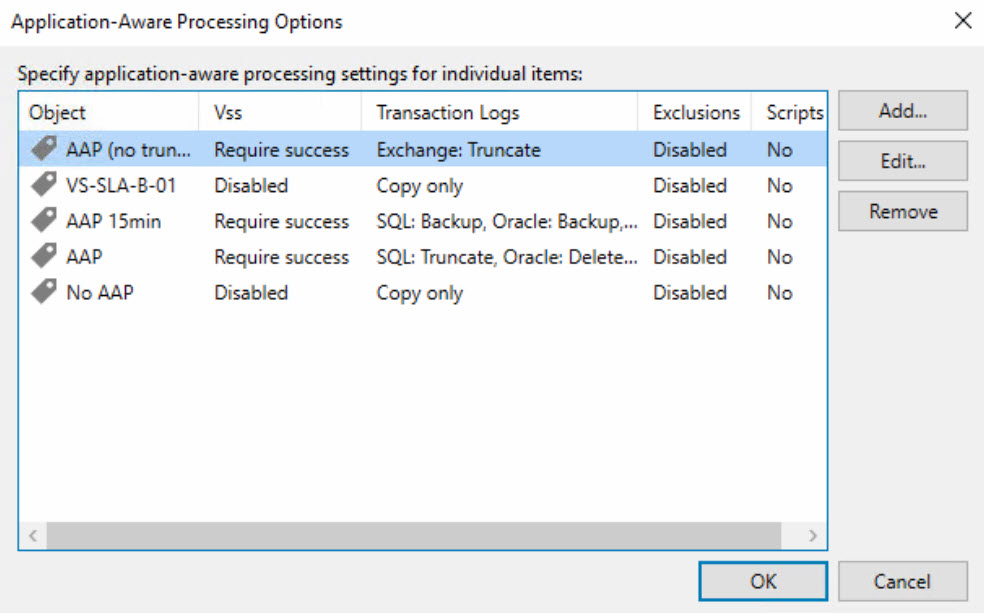
Hyper-V Job design:
HV-SLA-A-01 (Numbering continues): All VMs in the Hyper-V environment with SLA A (as mentioned above). VMs are directly assigned to the job. Application Aware Processing and Guest File System Indexing (GFSI) are manually assigned within the job.
Retention: 30 days on the SOBR (local hard drives of the Windows backup server).
HV-SLA-B-01 (Numbering continues): All VMs in the Hyper-V environment with SLA B (as mentioned above). VMs are directly assigned to the job. Application Aware Processing and Guest File System Indexing (GFSI) are manually assigned within the job.
Retention: 14 days on the SOBR (local hard drives of the Windows backup server).
HV-SLA-C-01 (Numbering continues): All VMs in the Hyper-V environment with SLA C (as mentioned above). VMs are directly assigned to the job. Application Aware Processing and Guest File System Indexing (GFSI) are manually assigned within the job.
Retention: 7 days on the SOBR (local hard drives of the Windows backup server).
Retentions for Backup Copy Jobs:
All the aforementioned backup data (for all environments, including agent backups) is intended to be copied to both the Linux server (Veeam Hardened Repository) and the Wasabi Cloud as per the customer’s request. Both copy repositories are immutable, and thus, the following retentions have been globally defined:
Veeam Hardened Repository (Linux): 7 days
Wasabi Cloud: Split into the mentioned 3 SLAs (A: 30 days, B: 14 days, C: 7 days)
Following discussions with the customer and my recommendation, it doesn’t make much sense to define significantly longer retentions. The primary goal is to quickly regain operational capabilities with the most current data in case of a disaster. Since modern attackers tend to reside within a system for more than half a year before launching an attack, extending backups to around 1 year would pose an often unmanageable cost factor for many clients, including this one.
In the event of cyberattacks, systems should ideally be reconfigured or rebuilt. Therefore, it makes sense to rely on the most up-to-date data, restoring only data and not operating systems or similar elements from the backup.
Other security configurations:
As is now the standard practice for many clients and service providers, all backups are stored in encrypted form. This applies to both backup jobs and backup copy jobs.
Experience has shown that it is advisable to use a password that meets current security standards but is also typeable on multiple keyboard layouts in case of a disaster, ensuring the possibility of recovery. The following rules have been defined for this purpose:
- 20 characters in length
- Comprised of letters, numbers, and special characters, limited to ! ? . – _ =
- A unique password for each system/component
Additionally, for this client, I have introduced the practice of renaming the local administrator account on all Windows systems, so that standard default values are not used.
Performance improvement:
The performance of vSphere backups was significantly improved due to SAN integration (FC-SAN) and the distribution of Veeam services across various components (virtual and physical, as mentioned above).
Performance before optimization: Processing Rate 568 MB/s, Throughput: 1 GB/s
Performance after optimization:

In the Hyper-V domain as well, performance was enhanced through reconfiguration and optimization of the network connectivity of the components. As mentioned earlier, OnHost proxies are employed here, placing the workload on the Hyper-V hosts.
Performance before optimization: Processing Rate 380 MB/s, Throughput: 2 GB/s
Performance after optimization:

Learnings and challenges:
The German midrange companies often experience rapid growth, but sometimes processes, documentation, and technical personnel struggle to keep up. Communication gaps may also occur occasionally. This scenario can be particularly challenging to address in infrastructure-related matters, as a good understanding of the systems, workloads, software, and hardware in use is essential. It’s necessary to define what needs to be backed up, when, and how. Systems must be prioritized, and, especially in the event of a restore, framework parameters and sequences must be defined – think of it as an “emergency handbook.”
In this case, the client faced personnel challenges, resulting in undocumented systems in the environment. Some of these systems were integrated into the existing backup infrastructure, but there was no information available about the applications and data residing on these systems. In some instances, access credentials were also missing. The colleagues who managed these applications and systems had already left the company.
It’s crucial in such large-scale projects to establish clear responsibilities and tasks. As a service provider, you can only advise the client and make recommendations. Tasks such as declaring SLAs and priorities, however, fall under the client’s responsibility and can vary significantly from one company to another.