Einer meiner größten Kunden bekommt in einem mehrwöchigen Projekt eine neue Backup- und DR-Infrastruktur auf Basis von Veeam Backup & Replication. Es handelt sich dabei und ein mittelständisches Unternehmen in der Handelsbranche mit weltweit über 30.000 Mitarbeitenden und mehreren Standorten in der EU.
Spannend ist, dass der Kunde eine Multi-Host Infrastruktur auf Basis von VMware vSphere, Microsoft Hyper-V (ohne Cluster-Funktionen), Oracle KVM und OVS betreibt. Es handelt sich in Summe um mehr als 30 Hypervisor-Systeme, die international betrieben werden. Neben den genannten Virtualisierungslösungen setzt der Kunde auch physikalische Systeme ein, die im Backup-Konzept betrachtet werden sollen.
Gemäß dem von mir standardmäßig angewendeten Veeam Advanced Deployment werden folgende Komponenten innerhalb der Veeam Infrastruktur bereitgestellt:
- VBR-Server (Veeam Management) – virtuell
- Repository- & Proxy-Server – physikalisch
- Enterprise Manager Server – virtuell
- Management-Server (Jump-Host) – virtuell
- Veeam Hardened Repository mit Immutability (Linux) – physikalisch
Die virtuellen Systeme werden auf der kundeneigenen vSphere-Infrastruktur betrieben, bei den physikalischen Servern handelt es sich um HPE Appollo Server mit lokalen HDDs als Massenspeicher. Es wurden insgesamt 2 RAID6-Sets pro System konfiguriert und mit einer Full Stripe Size von 1MB gemäß aktuellen Best Practices erstellt.
Als Datenbanksystem für Veeam VBR und den Enterprise Manager wird hier auf Grund der Größe und der Lizenzkosten für MSSQL auf PostgreSQL gesetzt, da die 10GB Limitierung für die MSSQL Express Edition nicht ausreichen.
Scale-Out Repositories:
Da es sich um insgesamt 2 RAID-Sets und somit um 2 logische Laufwerke pro Server handelt, wurde für beide Server je ein Scale-Out Repository konfiguriert, das als Target für Sämtliche Backup-Jobs und Backup-Copy-Jobs agiert.



Veeam Proxies:
Da der physikalische Windows-Repository-Server eine redundante Anbindung an die existierende SAN-Infrastruktur hat und somit auch die Storages für die vSphere-Umgebung so konfiguriert wurden, dass sie dem Server den Speicherplatz präsentieren, kann hier ein Direct SAN Access angewendet werden. Somit ist dieser Server auch als Veeam Proxy konfiguriert. Da die Hardware hinsichtlich der Compute-Performance großzügig ausgestattet wurde, wird dieser auch als Proxy für Agents und weitere Workloads verwendet. Dies ist gerade hinsichtlich Firewall-Regeln (Hardening) relevant.

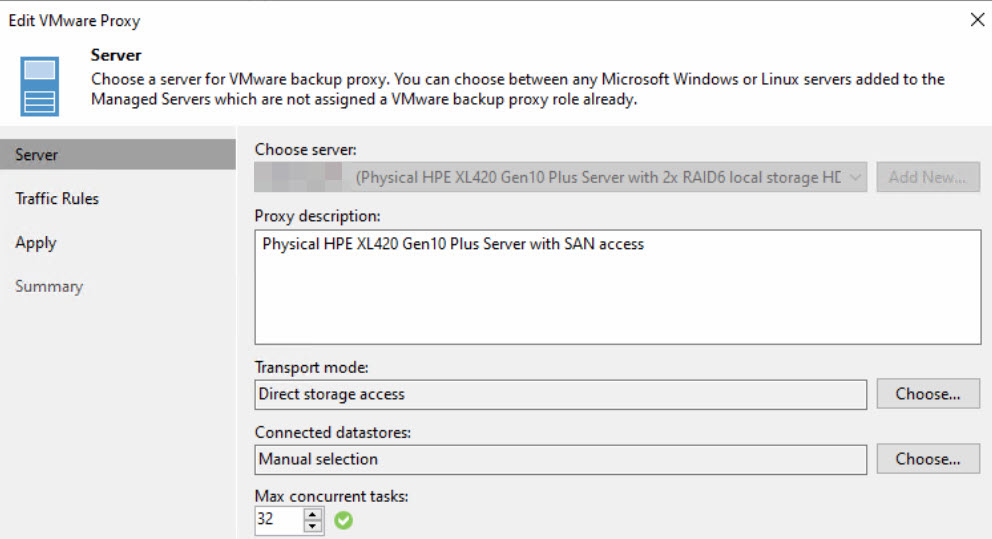
Als vPower Cache wurden hier übrigens zwei lokale SSDs im RAID1 konfiguriert, die ebenfalls als Pfad für die OS-Installation auf beiden Systemen dienen. Dieser Wunsch kam vom Kunden und wurde gerne umgesetzt.
Anbindung Veeam Hardened Repository:
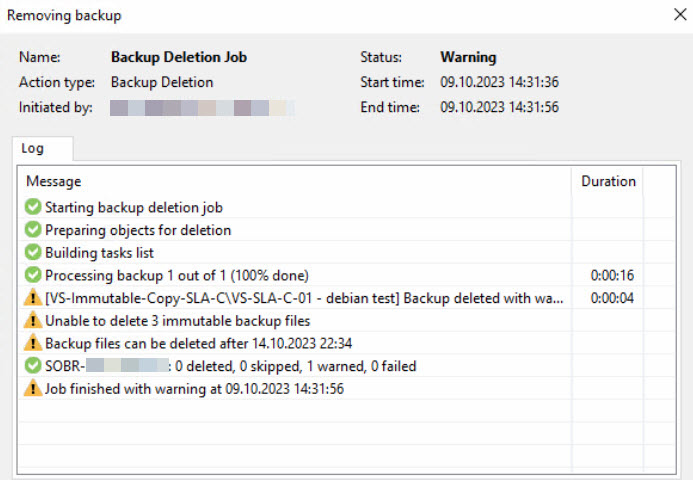
Um die erste Ebene mit erhöhter Sicherheit zu definieren, wurde wie oben erwähnt ein Hardware-Server mit großzügiger Computer- und Massenspeicher-Ausstattung als Veeam Hardened Repository-Server konfiguriert. Sowohl auf Wasabi als auch innerhalb von Veeam wurde die Immutability aktiviert, sodass die Backups für den angegebenen Zeitraum weder gelöscht noch verändert werden können.
Entsprechende Tests haben die Immutability der Backups bestätigt:
Dieses Linux-Repository dient in erster Linie der performanten und Compute-nahen Datenwiederherstellung, falls das primäre Backup-Repository (auf Windows-Basis) nicht zur Verfügung steht. Der Server selbst trägt lediglich die Repository-Rolle und ist nicht als Proxy o.ä. konfiguriert.
Zur Vermeidung der Gefahr, dass der Speicherplatz einen zu hohen Füllstand erreicht, hat der Kunde hier eine Retention von 7 Tagen sowohl für die Immutability als auch für die Backup Copy Jobs selbst in Richtung Veeam Hardened Repository definiert.
Anbindung Wasabi-Cloud:
Da der Kunde zwischen 100TB und 150TB kosteneffizient in eine Cloud-Lösung auslagern möchte, hat er von sich aus bereits erste Tests mit der Wasabi-Cloud durchgeführt. Auf Grund des guten Preis-Leistungsverhältnisses kann ich dies nur unterstützen und habe die Installation und Konfiguration der Lösung im Rahmen des Projektes überarbeitet.
Letztlich sollen 3 verschiedene Retentions innerhalb von Wasabi abgebildet werden und somit wurden 3 Buckets angelegt, eine pro Retention. Dies ist ein Abbild der bereits in den primären Backup Jobs abgebildeten Retentions / SLAs. Da Wasabi im Vergleich zu dem Veeam Hardened Repository auf Linux-Basis keine “harte” Beschränkung des Massenspeichers hat, konnten diese SLA-Retentions hier sauber abgebildet werden.
Auch hier wurde die Immutability aktiviert, sodass die Backups für den angegebenen Zeitraum weder gelöscht noch verändert werden können.
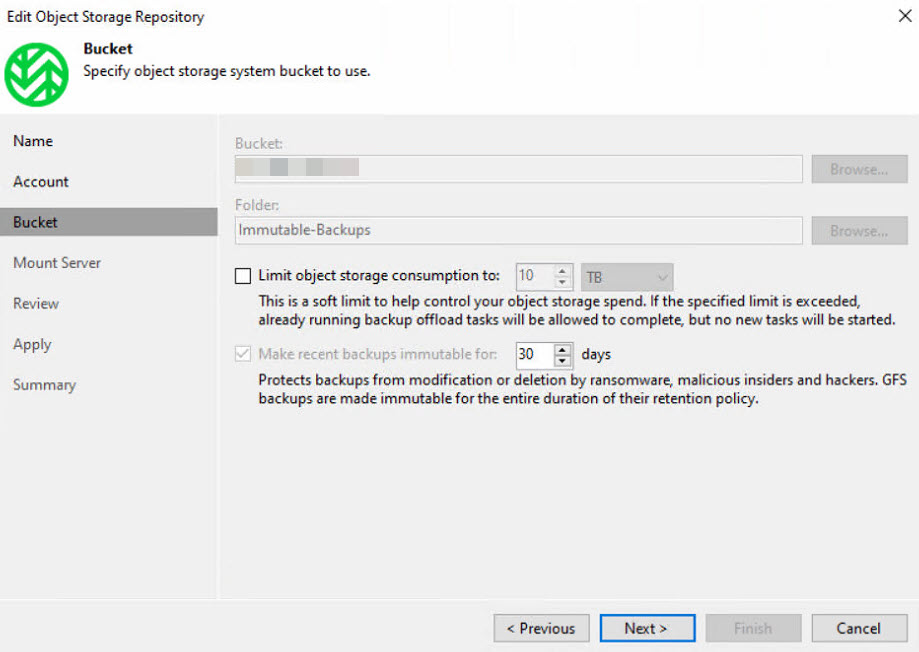
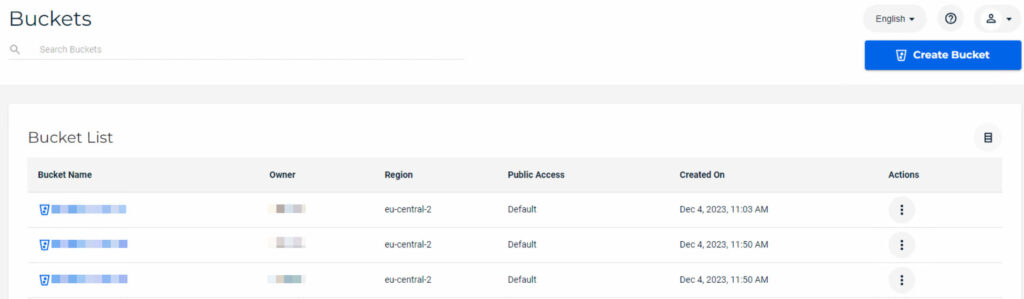
Wichtig ist, dass die Versionierung innerhalb der Wasabi-Cloud aktiviert werden muss, damit die Immutability im Veeam sauber konfiguriert werden kann! Innerhalb der Wasabi-Cloud wurden folgende Einstellungen gesetzt:
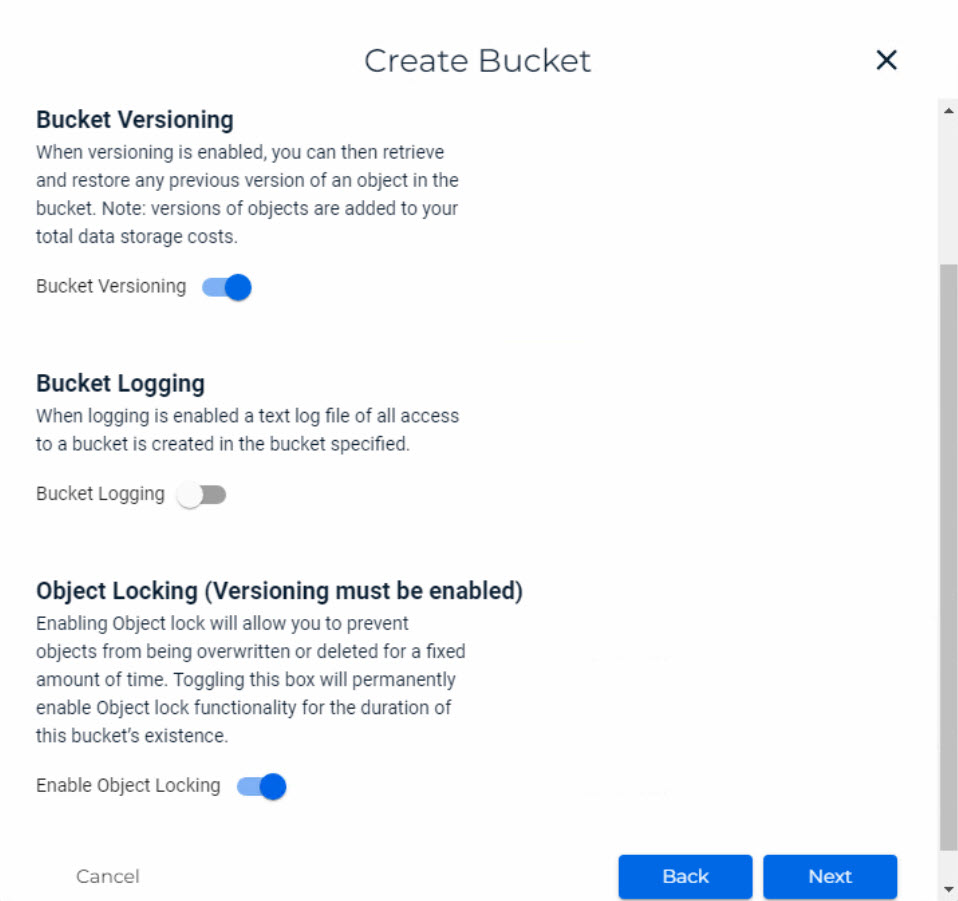
Anbindung vSphere-Umgebung:
Der Kunde nutzt eine vSphere-Infrastruktur basieren auf 6 ESXi-Hosts, diese wurden im Veeam angelegt. Wie üblich lege ich neben dem vCenter (der Kunde betreibt nur eines) auch die einzelnen ESXi-Hosts dediziert und per IP-Adresse an, sodass der Kunde im K-Fall auch bei ausgeschaltetem oder ausgefallenem vCenter Restores direkt zu einem der Hosts durchführen kann.
Anbindung Hyper-V Umgebung:
Da der Kunde ein Microsoft SQL AlwaysOn-Cluster auf insgesamt 4 Hyper-V Hosts betreibt und kein Microsoft Failover-Cluster für VMs besteht, wurden alle 4 Hosts als Standalone-Hosts in Veeam hinzugefügt. Da es sich um eine dedizierte und “isolierte” Umgebung handelt, die ausschließlich für das AlwaysOn-Cluster betrieben wird, ist hier keine zusätzliche Konfiguration durchgeführt worden.
Agent-Design (Protection Groups):
Eine Besonderheit bei diesem Kunden ist die EU-weit verteilte und für den Kunden selbst etwas undurchsichtige Außenstandort-Infrastruktur mit diversen OVS-, KVM- und physikalischen Systemen. Die Standorte sind durch den Kunden dazugekauft worden und die Betreuung der meisten dieser Systeme liegt in der Hand von Softwareherstellern oder dedizierten Partnern. Es handelt sich um Windows- und Linux-Systeme.
Das für die vSphere- und Hyper-V Jobs konfigurierte SLA-Prinzip soll hier nicht angewendet werden. Das liegt daran, dass die externen Dienstleister auf anderen Ebenen, u.a. auf Ebene der Datenbanken Backups durchführen.
Die Protection Groups wurden nach Standort definiert und folgendermaßen konfiguriert:
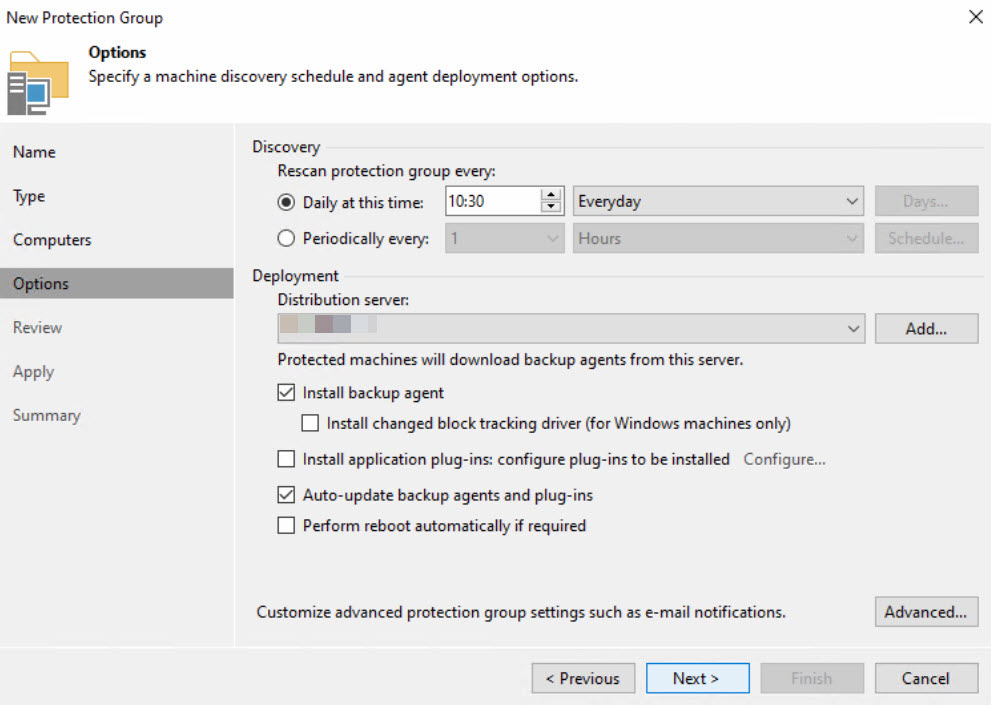
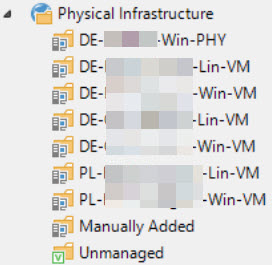
Der Ländercode fließt auf Wunsch des Kunden in den Namen der Protection Group ein.
Agent Backup Job Design:
Die Backup-Jobs für die Agents wurden aus Basis der Protection Groups erstellt und folgendermaßen konfiguriert:

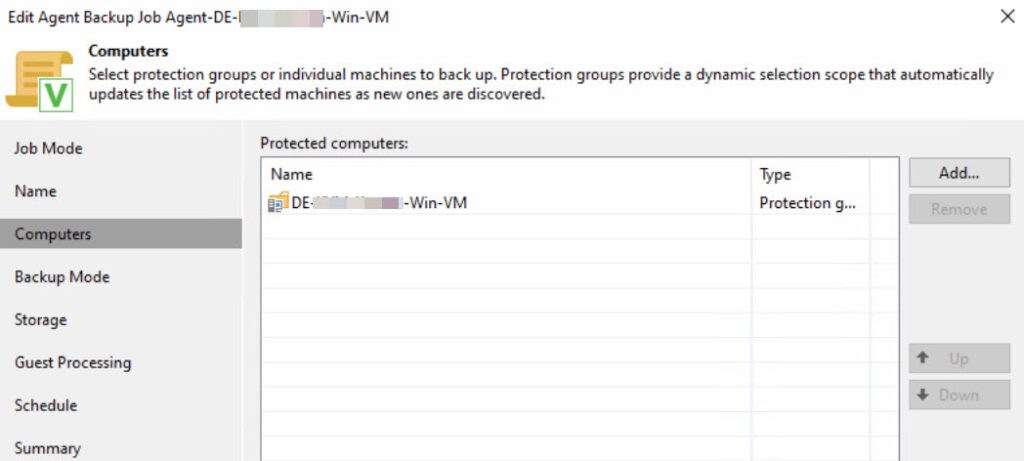
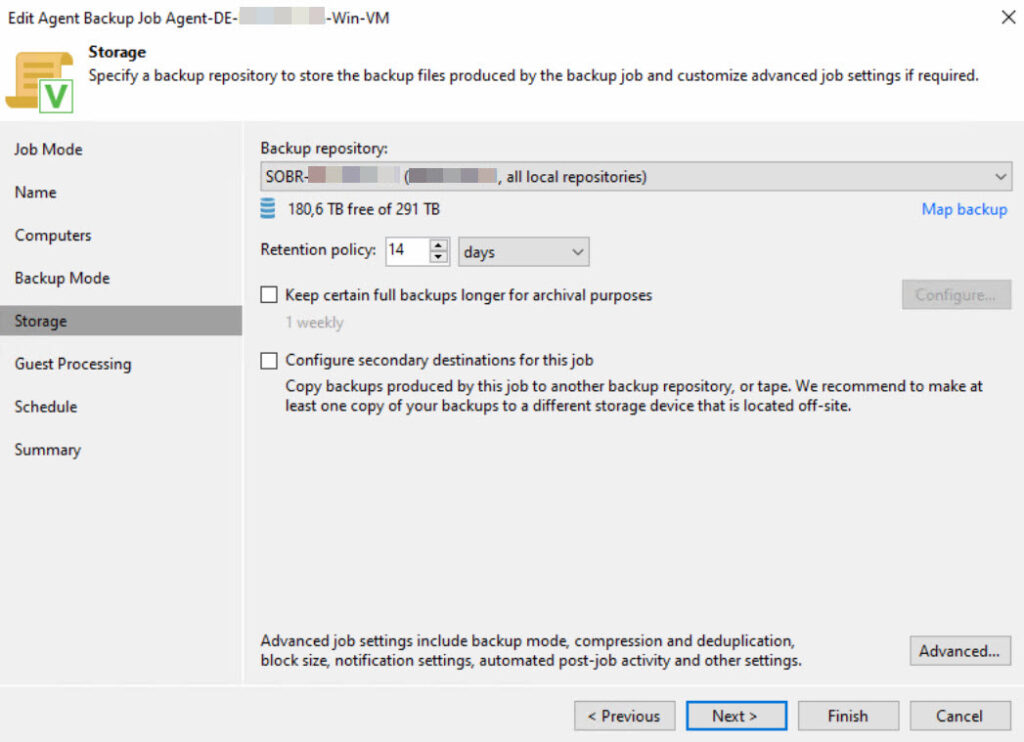
Wichtig: Da eine Protection Group zwar sowohl Windows- als auch Linux-Systeme enthalten kann aber ein Agent Backup Job entweder für Windows oder für Linux ausgelegt ist, muss dies beim Design der Protection Groups beachtet werden! Erfahrungsgemäß trenne ich die Gruppen immer nach Windows und Linux, um weniger Arbeit und eine bessere Transparenz bei der Anlage der Agent Backup Jobs zu haben.
Der Kunde hat keine festgelegten SLAs o.ä. für die Agents, demnach wird auf Wunsch des Kunden hier überall eine Retention von 14 Tagen erbracht.
SLA-Deklaration / vSphere-Tags:
Für die primären Systeme des Kunden – also die vSphere- und die Hyper-V Umgebung – wurde in Kooperation mit dem Kunden eine SLA-Deklaration vorgenommen. Diese Deklaration wurde in dem Job-Design und auch in das Design der vSphere-Tags übernommen, sodass folgende SLAs in diesem Fall auf beide Umgebungen angewendet werden:
SLA A (höchste Priorität): 30 Tage Retention im primären Repository, 7 Tage Immutable-Copy auf Linux, 30 Tage Immutable-Copy auf Wasabi
SLA B (mittlere Priorität): 14 Tage Retention im primären Repository, 7 Tage Immutable-Copy auf Linux, 14 Tage Immutable-Copy auf Wasabi
SLA C (geringe Priorität): 7 Tage Retention im primären Repository, 7 Tage Immutable-Copy auf Linux, 7 Tage Immutable-Copy auf Wasabi
Ziel ist, dass der Kunde im K-Fall gleichzeitig weiß, in welcher Reihenfolge er die Systeme wiederherstellen muss – beginnen mit SLA A. Da es im Hyper-V ohne den Einsatz des SCVMM keine Tags o.ä. gibt, wurde für Hyper-V eine manuelle Zuweisung der VMs in die entsprechenden Jobs vorgenommen.
vSphere Job-Design:
VS-SLA-A-01 (Nummerierung fortlaufend): Alle VMs der vSphere-Umgebung der SLA A (s.o.) auf Basis von gleichnamigen vSphere-Tags. Application Aware Processing und Guest File System Indexing (GFSI) werden ebenfalls per vSphere-Tag deklariert.
Aufbewahrung: 30 Tage auf dem SOBR (lokale Festplatten des Windows-Backupservers)
VS-SLA-B-01 (Nummerierung fortlaufend): Alle VMs der vSphere-Umgebung der SLA B (s.o.) auf Basis von gleichnamigen vSphere-Tags. Application Aware Processing und Guest File System Indexing (GFSI) werden ebenfalls per vSphere-Tag deklariert.
Aufbewahrung: 14 Tage auf dem SOBR (lokale Festplatten des Windows-Backupservers)
VS-SLA-C-01 (Nummerierung fortlaufend): Alle VMs der vSphere-Umgebung der SLA C (s.o.) auf Basis von gleichnamigen vSphere-Tags. Application Aware Processing und Guest File System Indexing (GFSI) werden ebenfalls per vSphere-Tag deklariert.
Aufbewahrung: 7 Tage auf dem SOBR (lokale Festplatten des Windows-Backupservers)
vSphere AAP und GFSI:
Sowohl AAP als auch GFSI wurden in der vSphere-Umgebung per Tag abgebildet und im Veeam folgendermaßen konfiguriert:
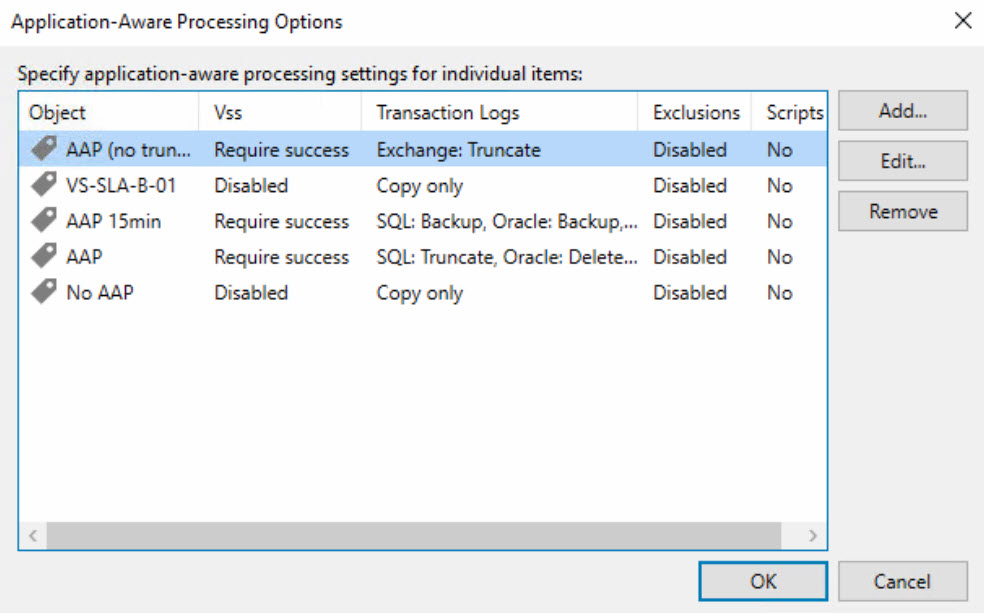
Hyper-V Job-Design:
HV-SLA-A-01 (Nummerierung fortlaufend): Alle VMs der Hyper-V Umgebung der SLA A (s.o.). Die VMs werden dem Job direkt zugewiesen. Application Aware Processing und Guest File System Indexing (GFSI) werden manuell innerhalb des Jobs zugewiesen.
Aufbewahrung: 30 Tage auf dem SOBR (lokale Festplatten des Windows-Backupservers)
HV-SLA-B-01 (Nummerierung fortlaufend): Alle VMs der Hyper-V Umgebung der SLA B (s.o.). Die VMs werden dem Job direkt zugewiesen. Application Aware Processing und Guest File System Indexing (GFSI) werden manuell innerhalb des Jobs zugewiesen.
Aufbewahrung: 14 Tage auf dem SOBR (lokale Festplatten des Windows-Backupservers)
HV-SLA-C-01 (Nummerierung fortlaufend): Alle VMs der Hyper-V Umgebung der SLA C (s.o.). Die VMs werden dem Job direkt zugewiesen. Application Aware Processing und Guest File System Indexing (GFSI) werden manuell innerhalb des Jobs zugewiesen.
Aufbewahrung: 7 Tage auf dem SOBR (lokale Festplatten des Windows-Backupservers)
Retentions für Backup Copy Jobs:
Sämtliche o.g. Backup-Daten (für alle Umgebungen inkl. der Agent-Backup) sollen auf Anforderung des Kunden sowohl auf den Linux-Server (Veeam Hardened Repository) als auch in die Wasabi Cloud kopiert werden. Beide Copy-Repositories sind Immutable und somit wurden folgende Retentions global definiert:
Veeam Hardened Repository (Linux): 7 Tage
Wasabi Cloud: Aufteilung in die o.g. 3 SLAs (A: 30 Tage, B: 14 Tage, C: 7 Tage)
Nach Rücksprache mit dem Kunden und meiner Empfehlung ist es wenig sinnvoll, die Retentions deutlich höher zu definieren. Es ist das primäre Ziel, im K-Fall schnell mit aktuellsten Daten wieder handlungsfähig zu werden. Da sich moderne Angreifer sowieso weit mehr als ein halbes Jahr im System aufhalten bevor ein Angriff gestartet wird, müsste man die Backups teilweise rund 1 Jahr vorhalten, was für viele Kunden – somit auch diesen Kunden – einen oft untragbaren Kostenfaktor darstellt.
Da Systeme gerade im Fall von Cyberangriffen sowieso neu aufgesetzt werden sollten / müssen, ist es sinnvoll, auf die aktuellste Datenbasis zurückzugreifen, jedoch nur die Daten und keine Betriebssysteme o.ä. aus dem Backup wiederherzustellen.
Sonstige Sicherheitskonfiguration:
Wie mittlerweile bei vielen Kunden und auch Dienstleistern als Standard definiert werden sämtliche Backups verschlüsselt abgelegt. Dies gilt sowohl für Backup Job als auch für Backup Copy Jobs.
Erfahrungsgemäß sollte hier ein Kennwort verwendet werden, welches zwar die aktuellen Sicherheitsstandards erfüllt, jedoch auch im K-Fall auf mehreren Tastatur-Layouts tippbar ist und somit die Wiederherstellung ermöglicht. Folgende Regeln habe ich hierfür definiert:
- 20 Zeichen
- Buchstaben, Zahlen und Sonderzeichen, diese jedoch beschränkt auf ! ? . – _ =
- eigenes Passwort für jedes System / jede Komponente
Außerdem habe ich bei diesem Kunden erstmalig den lokalen Administrator sämtlicher Windows-Systeme umbenannt, sodass mit den Standardwerten nicht mehr gearbeitet werden kann. Dies dient beispielsweise dazu, das System unanfälliger gegenüber Brute-Force Attacken zu machen.
Performance-Steigerung:
Die Performance der vSphere-Backups konnte auf Grund der SAN-Integration (FC-SAN) und auf Grund der Auslagerung von Veeam-Diensten auf verschiedene Komponenten (virtuell und physikalisch, siehe oben) signifikant gesteigert werden.
Performance vor der Optimierung: Processing Rate 568 MB/s, Throughput: 1 GB/s
Performance nach der Optimierung:

Ebenfalls im Hyper-V Bereich konnte durch eine Neukonfiguration und durch Optimierung der Netzwerkanbindung der Komponenten eine Steigerung der Performance erreicht werden. Wie oben erwähnt werden hier OnHost-Proxies verwendet, weshalb der Workload auf den Hyper-V Hosts liegt.
Performance vor der Optimierung: Processing Rate 380 MB/s, Throughput: 2 GB/s
Performance nach der Optimierung:

Learnings und Herausforderungen:
Gerade der Deutsche Mittelstand wächst – das oft sehr schnell. Prozesse, Dokumentationen und auch technisches Personal kommt oft nicht immer vollständig mit, es mag auch hin und wieder an Kommunikation mangeln. Dieses Szenario wird gerade bei infrastrukturellen Themen schwierig zu handeln, weil z.B. bei diesem Projekt eine gute Kenntnis über die eingesetzten Systeme, Workloads, Software und auch Hardware erforderlich ist. Es muss definiert werden, was wann und wie gesichert werden muss, die Systeme müssen Prioritäten zugeordnet werden und vor allem für den Restore-Fall müssen Rahmenparameter und Reihenfolgen definiert werden – Stichwort “Notfallhandbuch”.
In diesem Fall hatte der Kunde personelle Herausforderungen, sodass undokumentierte Systeme in der Umgebung existieren, die u.a. auch in das bestehende Backup eingeflossen sind, jedoch gab es keinerlei Information, welche Applikationen und Daten auf diesen Systemen bestehen, teilweise waren nicht einmal Zugangsdaten vorhanden. Entsprechende Kolleginnen und Kollegen, die entsprechende Applikationen und Systeme betreut haben, haben das Unternehmen längst verlassen.
Wichtig ist auch, dass in derart großen Projekten eine klare Trennung der Verantwortungen und Tätigkeiten vorgenommen wird. Als Dienstleister kann man den Kunden lediglich auf Dinge hinweisen bzw. Empfehlungen aussprechen, beispielsweise aber die Deklaration von SLAs und Prioritäten obliegt dem Kunden und ist natürlich auch von Unternehmen zu Unternehmen unterschiedlich.